-
torch의 데이터 분산 연산(DP 와 DDP)머신러닝 및 딥러닝 2022. 3. 25. 19:27
torch parallelism
Pytorch를 사용해 모델을 학습하다 보면 여러가지 병렬화를 사용합니다. 병렬화를 사용하는 이유는 크게 2가지로 나눠볼 수 있습니다.- 학습을 더 빨리 끝내기 위해
- 모델이 너무 커서 이를 분할하여 GPU에 올리기 위해
이번 블로그 글은 1. 학습을 더 빨리 끝내기 위해 사용할 수 있는 방법중 하나인 학습에 사용할 데이터를 병렬화 를 알아보도록 하겠습니다.
torch.nn.DataParallel- Single node 와 multi-GPU 에서 공작하는 multi-thread 모듈입니다.
- 이에 대한 동작방법을 그림으로 알아보겠습니다. 먼저 순전파 (Forward Pass) 입니다.
Forward Pass

설명의 용이성을 위해 여기선 GPU의 갯수를 4개로 하고 master gpu를 0번이라고 하겠습니다.
- GPU0 에 올라온 데이터 배치를 4등분 하여 각각 GPU0, GPU1, GPU2, GPU3 번에 전송합니다. 예를들어
batch size를 16,seq_len을 128이라고 하면 GPU0 에 16을 올리고 그 이후 GPU0, 1, 2, 3에 각각batch size4씩 할당해 주는 형식입니다. - Scatter 연산을 한다고 합니다.
- GPU0 에 올라와 있는 모델의 파라미터를 GPU0, 1, 2, 3 에 보내줍니다.
- Replicate 연산을 한다고 합니다.
- 각 디바이스에 데이터와 모델이 있으니 디바이스 내에서 forward 연산을 수행하여
Logits을 계산합니다. - 계산된
Logits을 GPU0 에 모아줍니다. - 이를 gather 연산을 한다고 합니다.
Logits으로 부터 Loss 를 계산합니다.
이 연산을 코드로 나타낸다면 다음과 같습니다.
import torch.nn as nn def data_parallel(module, inputs, labels, device_ids, output_device): # 입력 데이터를 device_ids들에 Scatter 합니다. inputs = nn.parallel.scatter(inputs, device_ids) # 모델을 device_ids들에 복제합니다. replicas = nn.parallel.replicate(module, device_ids) # 각 device 에 복제된 모델이 각 device의 데이터를 Forward 연산을 합니다. logit = nn.parallel.parallel_apply(replicas, inputs) # 모델의 logit을 output_device(하나의 device) 로 모아줍니다. logit = nn.parallel.gather(outputs, output_device) return logitsForward Pass 에 대해 알아봤으니 그다음 Backward Pass 의 방법에 대해 알아보도록 하겠습니다.
Backward Pass
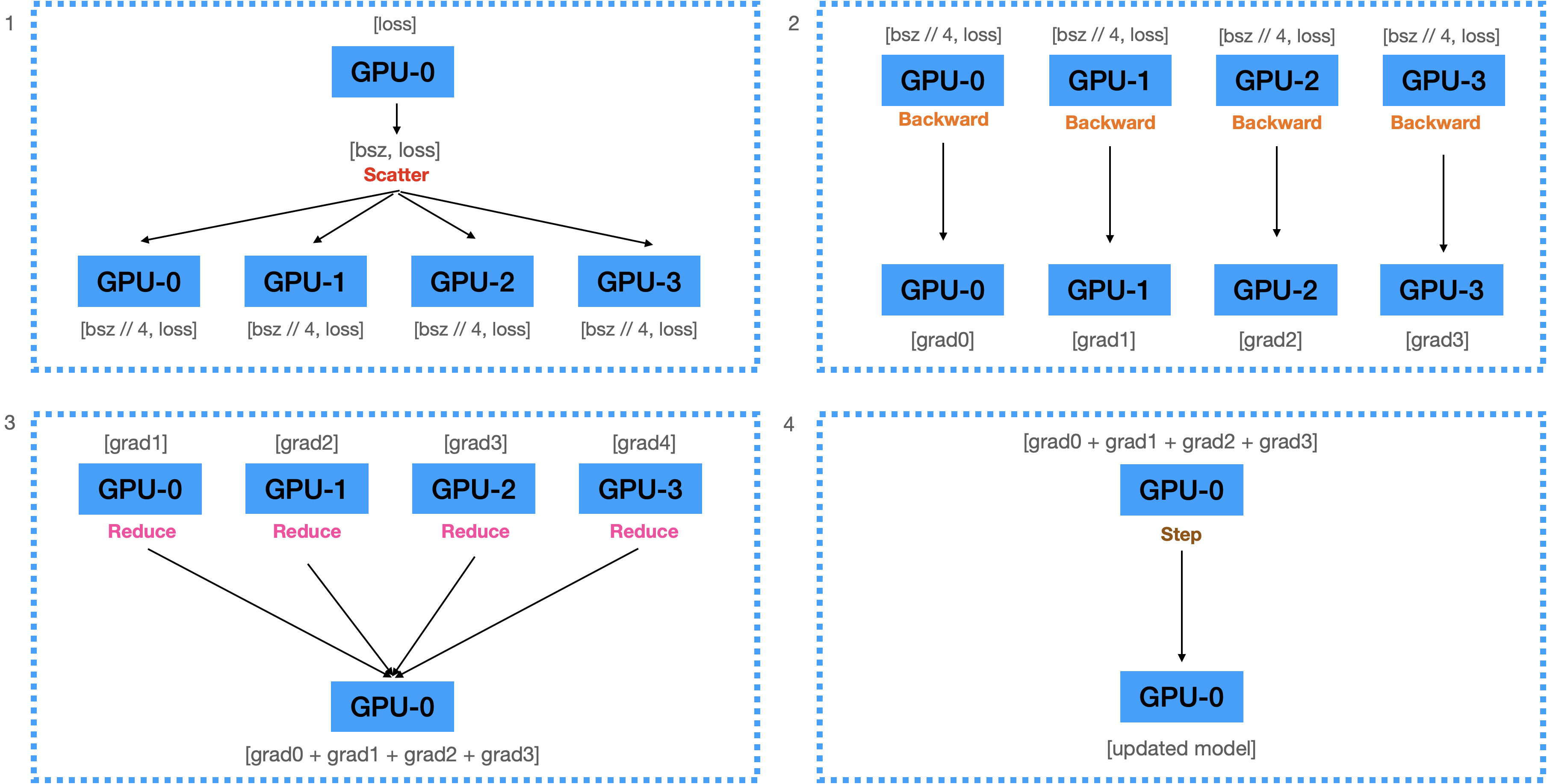
- 계산된 Loss 를 각 디바이스에 Scatter 해 줍니다.
- 전달받은 Loss를 이용해서 각 디바이스에서 Backward 를 수행하여 Gradients 계산합니다.
- 계산된 모든 Graidents를 GPU0으로 Reduce 해서 GPU0 에 모두 더한뒤 GPU의 수만큼으로 나눠 줍니다.
- Gradient를 이용해서 GPU0에 있는 모델을 업데이트 합니다.
코드
from torch import nn from torch.optim import AdamW from torch.utils.data import DataLoader from transformers import BertForSequenceClassification, BertTokenizer from datasets import load_dataset # 1. create dataset datasets = load_dataset("multi_nli").data["train"] datasets = [ { "premise": str(p), "hypothesis": str(h), "labels": l.as_py(), } for p, h, l in zip(datasets[2], datasets[5], datasets[9]) ] data_loader = DataLoader(datasets, batch_size=128, num_workers=4) # 2. create model and tokenizer model_name = "bert-base-uncased" tokenizer = BertTokenizer.from_pretrained(model_name) model = BertForSequenceClassification.from_pretrained(model_name, num_lables=3).cuda() # 3. make data parallel module # device ids: 사용할 디바이스 리스트 / output_device : 출력값을 모을 디바이스 model = nn.DataParallel(model, device_ids=[0, 1, 2, 3], output_device=0) # 4. create optimizer and loss function optimizer = AdamW(model.parameters(), lr=3e-5) loss_fn = nn.CrossEntropyLoss(reduction="mean") # 5. start training for i, data in enumerate(data_loader): optimizer.zero_grad() tokens = tokenizer( data["premise"], data["hypothesis"], padding=True, tuncation=True, max_length=512, return_tensors="pt", ) logits = model( input_ids=tokens.input_ids.cuda(), attention_mask=tokens.attention_mask.cuda(), return_dict=False, )[0] loss = loss_fn(logits, data["labels"].cuda()) loss.backward() optimizer.step() if i % 10 == 0: print(f"step:{i}, loss:{loss}") if i == 500: break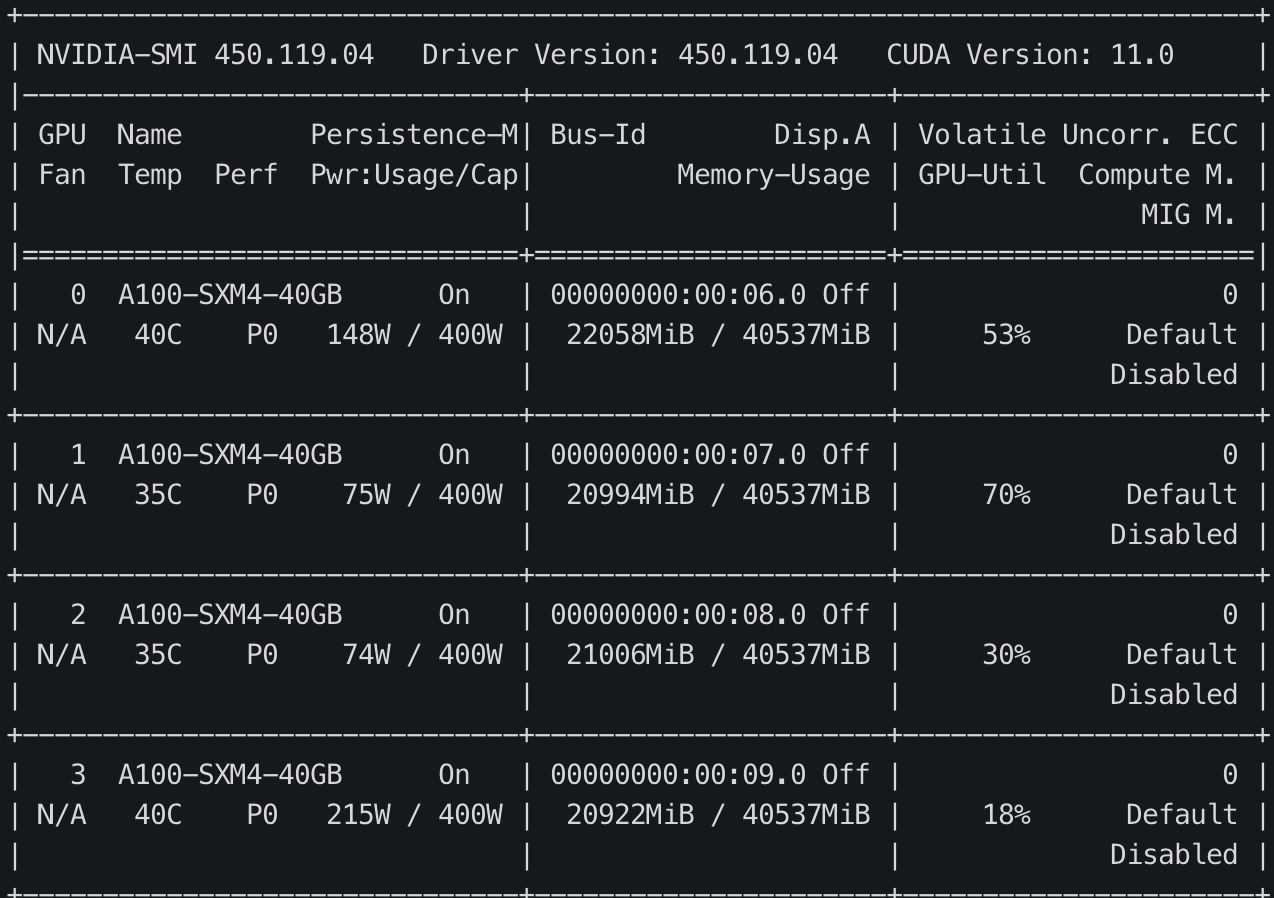
위의 그림처럼 Multi-GPU에서 학습이 잘 되는것을 볼 수 있습니다. 하지만 0번 GPU가 다른 GPU에 비해 많이 더 많은 메모리가 사용되고 있는것을 볼 수 있습니다. 앞에 설명했던 거처럼
forwarding연산시 logits을 하나의 GPU에 모은뒤 loss를 계산하기 때문에 위와 같은 현상이 일어납니다. 이 현상을 완화하기 위해선 각 GPU에서 loss 를 구한뒤 하나의 GPU에 loss를 모아준다면 해당 증상은 어느정도 완화가 될 수 있습니다.
각 GPU에서 loss 를 구하기 위해선 모델의
forward()에 이를 구현하면 됩니다.한가지 특이한 점은 이렇게 하면 Loss의 reduction이 2번 일어나게 됩니다. Multi-thread 에서
batch_size // 4개에서 loss가 나오기 때문에 한번의 Reduction 과정(그림에서 4번) 이 한번 일어나고 각 디바이스에서 출력된 4개의 Loss를 1개로 Reduction 하는 과정(그림에서 5번)이 다시 일어납니다. 얼핏보면 굉장히 비효율 적인거 같지만 Loss computation 부분을 병렬화 시킬 수 있고 0번 GPU에 가해지는 메모리 부담이 적기 때문에 훨씬 효율적입니다.from torch import nn class Model(nn.Module): def __init__(self): super().__init__() self.linear = nn.Linear(768, 3) def forward(self, inputs): outputs = self.linear(inputs) return outputs class ParallelLossModel(Model): def __init__(self): super().__init__() def forward(self, inputs, labels): logits = super().forward(inputs) loss = nn.CrossEntropyLoss(reduction="mean")(logits, labels) return lossNLP를 하시는 분들에게
HuggingFace라이브러리는 굉장히 익숙하고 많이 사용됩니다.HuggingFace의transformers모델들은 forward pass에서 Loss 를 구하는 기능이 내장되어 있습니다. 따라서 이러한 과정 없이transformers에서 학습을 진행하면 GPU 한쪽에 쏠리지 않고 학습이 가능합니다.# 1 ~ 4 까지 생략... # 5. start training for i, data in enumerate(data_loader): optimizer.zero_grad() tokens = tokenizer( data["premise"], data["hypothesis"], padding=True, truncation=True, max_length=512, return_tensors="pt", ) loss = model( input_ids = tokens.input_ids.cuda(), attention_mask = tokens.attention_mask.cuda(), labels = data["labels"] ).loss loss = loss.mean() # (4,) -> (1,) loss.backward() optimizer.step() if i % 10 == 0: print(f"step:{i}, loss:{loss}") if i == 300: break참고
loss.backward(): 기울기를 미분해서 Gradient를 계산optimizer.step(): 계산된 Gradient를 이용해서 파라미터를 업데이트- 계산 비용은
backward()>step()
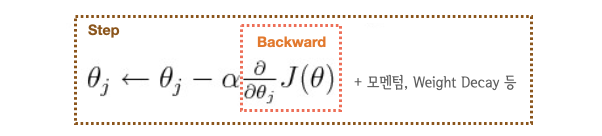
torch.nn.DataParallel 의 문제점
1) 멀티쓰레드 모듈이기 떄문에 Python 에서 효율적이 않다.
Python은 GIL (Global Interpreter Lock)에 의해 하나의 프로세스에서 동시에 여러개의 쓰레드가 작동할 수 없습니다. 따라서 근본적으로 멀티 쓰레드가 아닌 멀티 프로세스 프로그램 으로 만들어서 여러개의 프로세스를 동시에 실행하게 해야합니다.
2) 하나의 모델에서 업데이트 된 모델이 다른 device로 매 스텝마다 복제되어야 한다.
현재의 방식은 각 디바이스에서 계산된
Gradient를 하나의 디바이스 모아서(Gather) 업데이트 하는 방식이기 때문에 업데이트 된 모델을 매번 다른 디바이스들로 복제(Broadcast) 해야 합니다. 하지만 이 과정은 매우 비쌉니다. 그렇다면 이 방법을 어떻게 효율적으로 해결 할 수 있을까요?Gradient를Gather하지 않고 각 GPU에서 자체적으로step()을 수행한다면 모델을 매번 복제하지 않아도 되지 않을까요?Solution => All-reduce
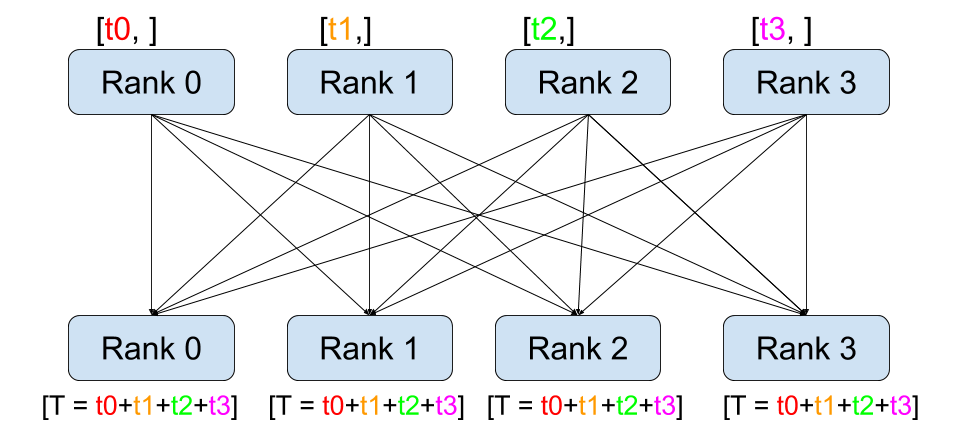
정답은 reduce 를 수행한뒤 계산된 결과를 모든 디바이스에 복사하는
All-reduce연산을 하는 방법을 사용하면 이를 완화 시킬 수 있습니다.코드로 그 예시를 같이 확인해보도록 하겠습니다.
import torch import torch.distributed as dist dist.init_process_group("nccl") rank = dist.get_rank() torch.cuda.set_device(rank) tensor = torch.ones(2,2).to(torch.cuda.current_device()) * rank # rank == 0 => [[0, 0], [0, 0]] # rank == 1 => [[1, 1], [1, 1]] # rank == 2 => [[2, 2], [2, 2]] # rank == 3 => [[3, 3], [3, 3]] dist.all_reduce(tensor, op=torch.distributed.ReduceOp.SUM) print(f"rank {rank}: {tensor}\n) # result rank 1: tensor([[6., 6.], [6., 6.]], device='cuda:1') rank 2: tensor([[6., 6.], [6., 6.]], device='cuda:2') rank 0: tensor([[6., 6.], [6., 6.]], device='cuda:0') rank 3: tensor([[6., 6.], [6., 6.]], device='cuda:3')이렇게 각 GPU에서 계산
Loss를 맞춰줄 수 있다면 자체적으로step()을 수행할 수 있습니다. 그러면 매번 모델을 특정 디바이스로부터 복제해 올 필요가 없습니다. 따라서All-reduce를 활용하는 방식으로 기존 방식을 개선해 볼 수 있습니다.그러나 All-reduce는 매우 비싼 연산입니다. 내부 구현이 어떻게 이루어져있는지 같이 한번 살펴보죠
1. Reduce + Broadcast 구현방식

해당 방식은 각 GPU의 연산들을 하나의 마스터 프로세스 GPU에 보내 마스터 프로세스가 연산을 완료후 각 GPU에 연산될 결과값을 보내주는 방식입니다. 하지만 이방식은 마스터 프로세스의 부하가 심해지며, 수가 증가할 때 마다 통신 비용이 매우 커집니다.
2. All to All 구현 방식

해당 방식은 모든 디바이스가 개별통신을 하여 각각의 값을 전송하는 방식입니다. n 개의 장비가 있을 때, 약 n^2 의 통신이 발생합니다.
3.
torch.nn.parallel.DistributedDataParallel(DDP)Ring All-reduce
해당 방식은 2017년 바이두의 연구진이 개발한 새로운 연산입니다. 기존 방식들에 비해 월등한 성능을 보여줬기 때문에 DDP 개발의 핵심이 되었습니다.

위 연산방법을 사용하면
- 마스터 프로세스를 사용하지 않기 때문에 특정 device로 부하가 쏠리지 않습니다.
- All-to-All 처럼 비효율적인 연산을 수행하지 않습니다.
- 효율적인 방식으로 모든 device의 파라미터를 동시에 업데이트하기 때문에 모델을 매번 DP 처럼 replicate하지 않아도 됩니다.
torch.nn.parallel.DistributedDataParallel(DDP)DDP 는 기존
DataParallel의 문제를 개선하기 위해 등장한 데이터 병렬처리 모듈이며single/multi-node & multi-GPU에서 동작하는multi-process모듈입니다.All-reduce활용하게 되면서 마스터 프로세스의 개념이 없어졌기 때문에 학습과정이 매우 심플하게 변합니다.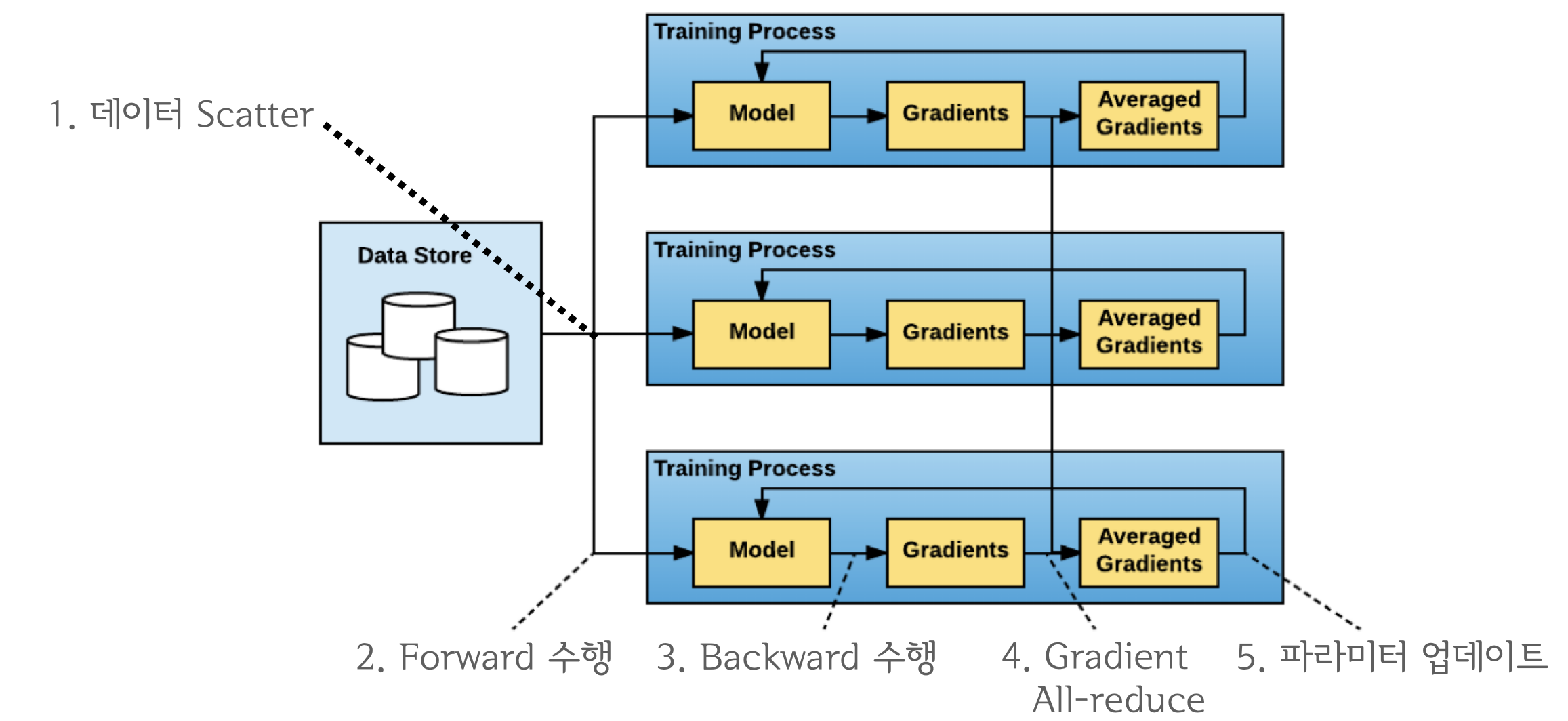
import torch import torch.distributed as dist from torch.nn.parallel import DistributedDataParallel from torch.optim import AdamW from torch.utils.data import DataLoader, DistributedSampler from transformers import BertForSequenceClassification, BertTokenizer from datasets import load_dataset # 1. initialize process group dist.init_process_group("nccl") rank = dist.get_rank() torch.cuda.set_device(rank) device = torch.cuda.current_device() world_size = dist.get_world_size() # 2. create dataset datasets = load_dataset("multi_nli").data["train"] datasets = [ { "premise": str(p), "hypothesis": str(h), "labels": l.as_py(), } for p, h, l in zip(datasets[2], datasets[5], datasets[9]) ] # 3. create DistributedSampler # DistributedSampler 는 데이터를 쪼개서 다른 프로세스로 전송하기 위한 모듈입니다. sampler = DistributedSampler( datasets, num_replicas=world_size, rank=rank, shuffle=True, ) data_loader = DataLoader( datasets, batch_size=32, num_workers=4, sampler=sampler, shuffle=False, pin_memory=True, ) # 4. create model and tokenizer model_name = "bert-base-cased" tokenizer = BertTokenizer.from_pretrained(model_name) model = BertForSequenceClassification.from_pretrained(model_name, num_labels=3).cuda() # 5. make distributed data parallel module model = DistributedDataParallel(model, device_ids=[device], output_device=device) # 6. create optimizer optimizer = AdamW(model.parameters(), lr=3e-5) # 7. start training for i, data in enumerate(data_loader): optimizer.zero_grad() tokens = tokenizer( data["premise"], data["hypothesis"], padding=True, truncation=True, max_length=512, return_tensors="pt", ) loss = model( input_ids=tokens.input_ids.cuda(), attention_mask=tokens.attention_mask.cuda(), labels=data["labels"], ).loss loss.backward() optimizer.step() if i % 10 == 0 and rank == 0: print(f"step: {i}, loss: {loss}") if i == 300: break해당 파이썬 코드를 실행할땐
python 파일명 (Ex. train.py)으로 실행하면 안됩니다. 멀티프로세스 애플리케이션 이개 때문에torch.distributed.launch를 사용해아합니다.python -m torch.distributed.launch --nproc_per_node=GPU_갯수 파일명파이썬 코드를 보면 그래서 결론적으로 어디서
All_reduce가 일어나는 거지? 라는 생각이 드실 수 있습니다.All_reduce의 개념을 생각해보면loss.backward또는optimizer.step다음에 실행될 거 같습니다. DDP 는loss.backward()를 수행한 뒤all-reduce를 수행합니다. 그 이유는 아래 그림을 참고 하시면 이해 하실 수 있습니다.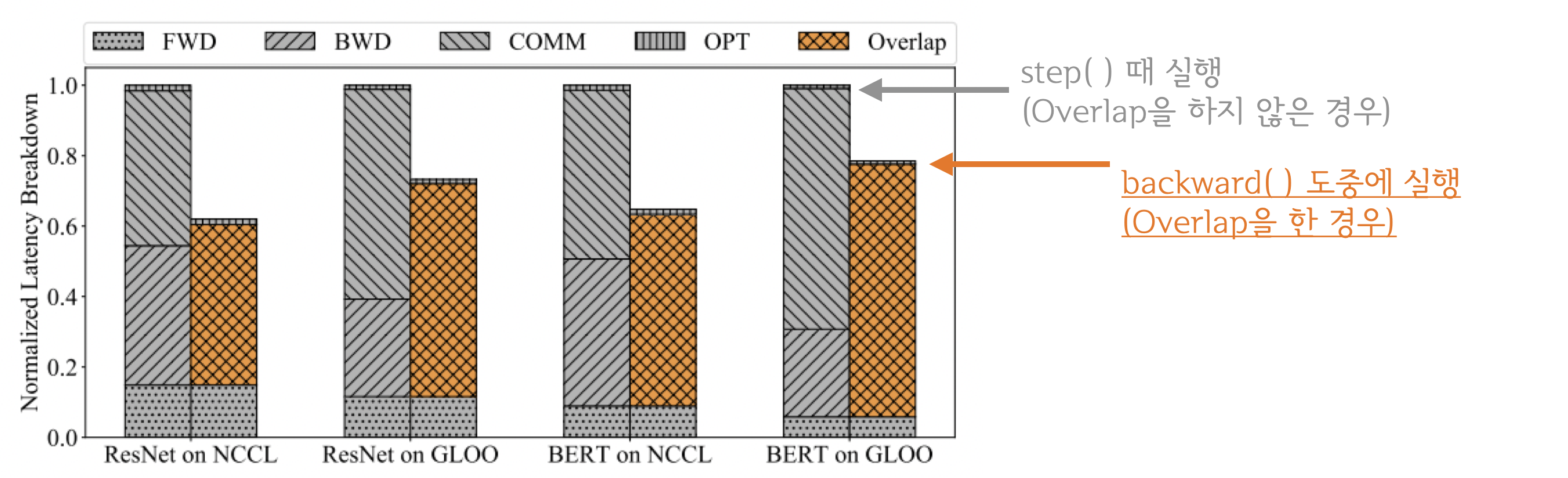
all_reduce는 네트워크 통신이고backward(), step()등은 GPU 연산이기 때문에 동시에 처리할 수있습니다. 이들을 중첩시키면 즉, computtation과 communication을 최대한으로 overlap되기 때문에 연산 효율은 크게 증가합니다.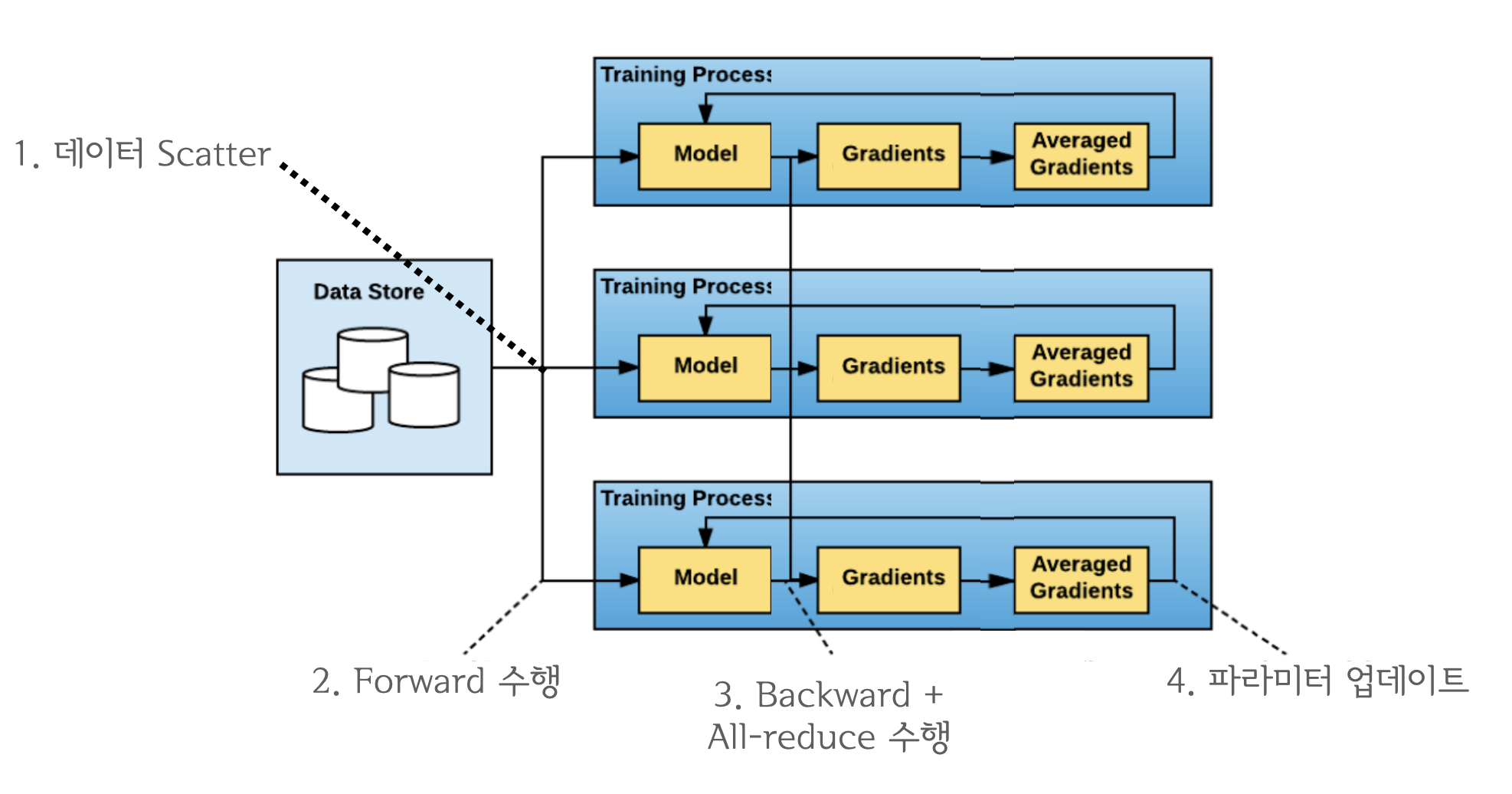
궁금증
- Q1:
backward()연산 중에 Gradient가 모두 계산되지 않았는데 어떻게all-reduce를 수행합니까?- A1:
backward()연산은 뒤쪽 레이어부터 순차적으로 이루어지기 때문에 계산이 끝난 레이어를 먼저 전송하면 됩니다.
- A1:
- Q2 : 그렇다면 언제마다
all-reduce를 수행하나요? 레이어 마다 이루어지나요?- A2: 아닙니다. Gradient Bucketing 을 수행합니다. Bucket이 가득차면 All-reduce를 수행합니다.
Gradient Bucketing
- Gradient Bucketing은 Gradient를 일정한 사이즈의 Bucket에 저장해두고 가득차면 다른 프로세스로 전송하는 방식입니다. 가장 먼저
backward()연산 도중 뒤쪽부터 계산된 Gradient들을 차례대로 bucket 에 저장하다가 bucket의 용량이 가득차면 All-reduce 를 수행해서 각 device에 Gradient의 합을 구한 뒤 디바이스(GPU) 의 갯수로 나눠 Gradient의 평균 값을 전달합니다. 그림때문에 헷갈릴 수 있는데, bucket에 저장되는 것은 모델의 파라미터가 아닌 해당 레이어에서 출력된 Gradient입니다. 모든 bucket은 일정한 사이즈를 가지고 있으면bucket_size_mb인자를 통해 mega-byte 단위로 용량을 설정 할 수 있습니다.
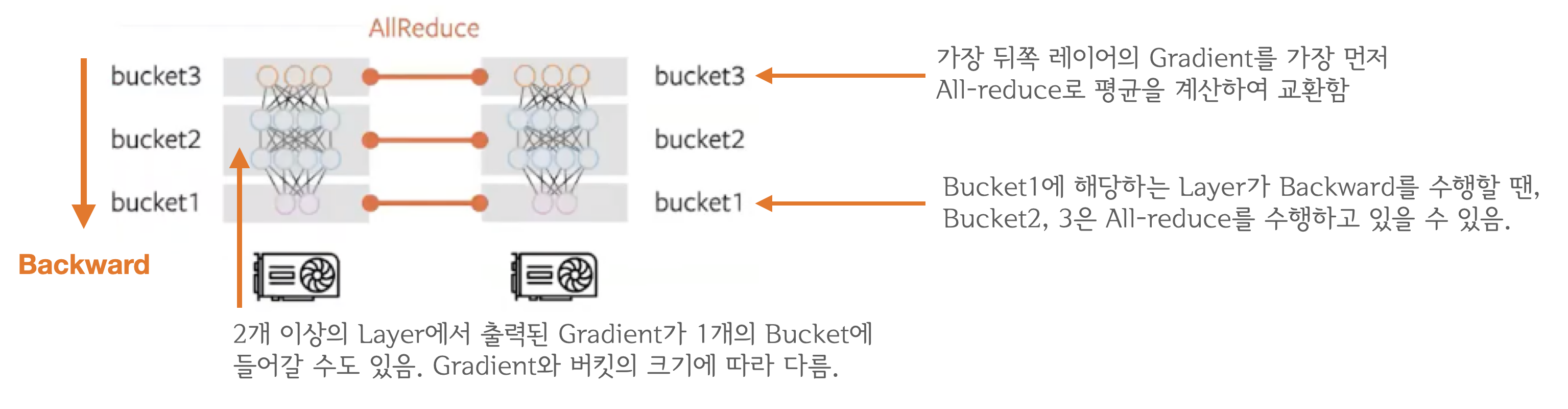
참고
'머신러닝 및 딥러닝' 카테고리의 다른 글
Dialogflow (0) 2022.03.10 Tokenizer에 종류 (0) 2022.03.01 클라우드 환경에서 딥러닝 모델을 띄울 때 주의해야 할점과 나의 환경 (0) 2021.08.31 BlenderBot 2.0 : An open source chatbot that builds long-term memory and searches the internet (0) 2021.07.19 ROUGE (0) 2021.07.16