-
해시 테이블(해시 맵)자료구조 2021. 1. 22. 01:09
정의
- 해시 테이블 또는 해시 맵은 키를 값에 매핑할 수 있는 구조인, 연관 배열 ADT를 구현 하는 자료구조이다.
특징
- 대부분의 연산이 분할 상환 분석에 따른 시간 복잡도가 O(1)이기 때문에 데이터 양과 관계없이 빠른 성능 기대 가능
해시함수
- 임의 크기 데이터를 고정 크기 값으로 매핑하는데 사용할 수 있는 함수
- 사용되는곳: 체크섬, 손실 압축, 무작위화 함수, 암호
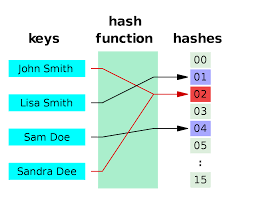
해싱 위 그림은 해시 함수를 통해 키가 해시 값을 변경되는 과정을 도식화 한것이다. 이처럼 해시 테이블을 인덱싱하기 위해서 해시 함수를 사용하는 것을 해싱이라고 한다. 여러 해시함수들 중에서 단순하고 널리쓰이는 정수형 해싱 기법인 모듈 연산을 이용한 나눗셈 방식 하나만 살펴보자. 수식은 아래와 같다.
H(x) = x mod m
여기서 H(x)는 입력값 x의 해시 함수를 통해 생성된 결과다. m은 해시 테이블의 크기로, 일반적으로 2의 멱수(32, 64, 128,....)에 가깝지 않은 소수를 택하는 것이 좋다.여기서 x는 어떤 간단한 규칙을 통해 만들어낸 충분히 랜덤한 상태의 키 값이다.
성능 좋은 해시 함수 특징
- 해시 함수 값 충돌의 최소화
- 쉽고 빠른 연산
- 해시 테이블 전체에 해시 값이 고르게 분포
- 사용할 키의 모든 정보를 이용하여 해싱
- 해시 테이블 사용 효율이 높음
왜 충돌을 경계해야 할까?
비둘기집을 생각해보자 만약 10개의 비둘기 집이 있고 9개의 집이 비둘기로 가득 찬 상황일때 한마리가 바로 그 빈 집을 찾아가면 가장 빠르게 끝낼수 있지만 worst case인 경우 모든 비둘기집을 다 들어가고 마지막에 빈집으로 가면 너무 느리게 끝날 것이다.
즉, 충돌이 일어나면 추가 연산을 해 속도가 느려지므로 이를 경계해야한다.
데이터가 적고 해쉬테이블의 사이즈가 그보다 클 때에도 좋은 해쉬함수를 사용해야 할까?
이에 대한 궁금증을 해결해주는 실험이 있다. 바로 생일 문제이다. 사람이 최소 366명이어야 같은 생일인 사람이 생길 확률이 100%가 된다. 예를들어, 30명이 모였다고 하여도 같은 생일 있을 확률은 극히 적어보인다. 하지만 이를 반증 하듯 23명만 되어도 같은 생일일 확률이 50%가 넘어간다.

23명만 모여도 생일이 가은 확률이 50%를 넘어간다. 이를 해쉬테이블에 적용시켜보았을때 충돌(같은 생일일 확률)은 생각보다 쉽게 일어난다. 따라서 충돌을 최소화 하는것이 무엇보다 중요하다.
로드 팩터
- 해시 테이블에 저장된 데이터 개수 n을 버킷의 개수 k로 나눈 값이다. (load factor = n/k)
로드팩터 비율에 따라서 해시 함수를 재작성해야 하는지 또는 해시 테이블의 크기를 조정해야 할지를 결정한다. 또한 이 값은 해시 함수가 키들을 잘 분산해주는 말하는 효율석 측정에서도 사용된다.
일반적으로 로드 팩터가 증가할 수록 해시 테이블의 성능은 점점 감소하게 되며, 자바 10의 경우 로드팩터가 0.75를 넘을경우 동적 배열 처럼 해시 테이블의 공간을 재 할당한다.
충돌
충분히 좋은 해시 함수를 사용하더라도 충돌은 발생하게 된다.
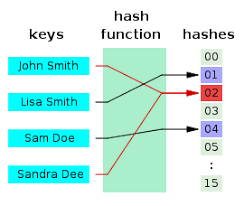
충돌 이렇게 충돌이 발생할 경우 개별 체이닝과 오픈 어드레싱 방법으로 해결 할수가 있다.
개별 체이닝

개별 체이닝 해시 테이블의 기본 방식이기도 한 개별 체이닝은 충돌 발생 시 이 그림과 같이 연결 리스트로 연결하는 방식이다. 충돌이 발생한 윤아와 서현은 윤아의 다음 아이템이 서현인 형태로 서로 연결리스트로 연결되었다. 이렇게 기본적인 자료구조와 임의로 정한 간단한 알고리즘만 있으면 되어 개별 체이닝 방식은 인기가 높다.
간단한 원리를 요약하자면
1. 키의 해시값을 계산한다.
2. 해시 값을 이용해 비열의 인덱스를 구한다.
3. 같은 인덱스가 있다면 연결리스트로 연결한다.잘 구현한 경우 대부분의 탐색은 O(1)이지만 최악의 경우, 즉 모든 해시 충돌이 발생했다고 가정할 경우 O(n)이 된다. 자바 8에서는 연결 리스트 구조를 최적화해서 데이터의 개수가 많아지면 레드-블랙 트리에 저장하는 형태로 병행하여 사용하였다.
오픈 어드레싱
충돌 발생 시 탐사를 통해 빈 공간을 찾아나서는 방식으로 사실상 무한정 저장할 수 있는 체이닝 방식과 달리, 오픈 어들싱 방식은 전체슬롯의 개수 이상은 저장 할 수 없다. 충돌이 일어나면 테이블 공간 내에서 탐사를 통해 빈 공간을 찾아 해결하며, 이 때문에 개별 체이닝 방식과 달리, 모든 원소가 반드시 자신의 해시값과 일치하는 주소에 저장된다는 보장은 없다.

오픈 어드레싱 여러 가지 오픈 어들싱 방식 중 가장 간단한 방식인 선형 탐사 방식은 충돌이 발생할 경우 해당 위치부터 순차적으로 탐사를 하나씩 진행한다. 특정 위치가 선점 되어 있으면 바로 그 다음 위치를 확인하는 식이다. 이렇게 탐사를 진행하다가 비어 있는 공간을 발견하면 삽입하게 된다. 가장 가까운 다음 빈 위치를 탐사해 새 키를 삽입한다. 그림에서 보면 윤아와 서현은 해시값이 동일한 2로 충돌이 발생했고 다음번 빈 위치를 탐색하며 그 다음 위치인 3에 서현이 들어가게 된다. 이처럼 선형 탐사 방식은 구현이 간단하며 의외로 전체적인 성능이 좋은 편이다.
선형탐사의 한가지 문제점은 해시 테이블에 저장되는 데이터들이 그게 분포되지 않고 뭉치는 경향이 있다는 점이다.
해시 테이블 여기저기에 연속된 데이터 그룹이 생기는 현상을 클러스터링이라 하는데 클러스터 들이 점점 커지게 되면서 인근 클러스터들과 서로 합쳐지는 일이 발생한다. 그렇게 되면 해시 테이블의 특정 위치에는 데이터가 몰리게 되고 다른위치에는 상대적으로 데이터가 거의 없는 상태가 된다. 이러한 클러스터링 현상은 탐사 시간을 오래 걸리게 하며 전체적으로 해싱 효율을 떨어뜨리는 원인이 된다.
이미 알아차렸겠지만 오픈 어드레싱 방식은 버킷 사이즈보다 큰 경우에는 삽입할 수 없다. 따라서 일정 이상 채워지면 즉, 로드 팩터 비율을 넘어서게 되면, Growth Factor의 비율에 따라 더 큰 크기의 또 다른 버킷을 생성한 후 여기에 새롭게 복사하는 리해싱 작업이 일어난다. 이는 동적배열에서 공간이 가득 찰 경우, 더블링으로 새롭게 복사해서 옮겨가는 과정과 유사하다.
파이썬은 딕셔너리가 해시테이블로 구현되었다. 그럼 딕셔너리는 충돌 시 어떤 방식을 사용할까? 딕셔너리는 체이닝 시 malloc으로 메모리를 할당하는 오버헤드가 높아 오픈 어드레싱 방식을 사용하였다. 앤드큐 커클링은 연결리스트를 만들기 위해서는 추가 메모리 할당이 필요하고, 추가 메모리 할다은 상대적으로 느린 작업이기 때문에 이를 택하지 않았다고 기술했다.

체이닝과 오픈 어드레싱 빅 그림과 가이 오픈 어드레싱의 한방식인 선형 탐사 방식은 일반적으로 체이닝에 비해 성능이 더 좋다. 스러나 슬롯의 80%이상이 차게 되면 급격한 성능 저하와 더불어 로드팩터 1이상은 저장 할 수 없다. 따라서 루비나 파이썬 같은 모던 언어들은 오픈 어드레싱 방식을 택해 성능을 높이는 대신 로드팩터를 작게 잡아 성능 저하 문제를 해결한다.(파이썬은 로드팩터가 0.66이다.)