서브워드 토크나이저
기계에 아무리 많은 단어들을 학습시킨다고 하여도 신조어와 단어사이즈의 한계등으로 인하여 Out-Of-Vocabularay가 발생한다. 이를 해결하기 위해서 서브워드 분리작업이라는 것이 만들어 졌다.
서브워드 분리 작업은 하나의 단어는 더 작은 단위의 의미있는 여러 서브워드들의 조합으로 구성된 경우가 많기 때문에, 하나의 단어를 여러 서브워드로 분리해서 단어를 인코딩 및 임베딩 하겠다는 의도를 가진 작업이다.
이를 통해 OOV, 희귀 단어, 신조어 문제를 완화 시킬 수 있다. 이런 서브워드 토크나이저에는 대표적으로 Sentencepiece 알고리즘과 BPE를 활용한 WordPiece가 있다.
BPE(Byte Pair Encoding)
BPE는 1994년에 제안된 데이터 압축 알고리즘으로 연속적으로 가장 많이 등장한 글자의 쌍을 찾아서 하나의 글자로 병합하는 방식을 수행한다. 태생이 압축알고리즘 때문에 여기서는 글자라는 단어보다 바이트라는 표현을 사용했다. 예시를 들어 설명해보겠다. 참고로 GPT-2에서도 BPE를 사용했다고 한다.
aaabdaaabac
이 단어에서 가장 많이 등장하는 바이트 쌍(byte pair)은 'aa'이다. 이 'aa'를 하나의 바이트인 'Z'로 치환해보자
ZabdZabac
Z='aa'
가 된다. 위의 단어에서는 바이트 쌍(byte pair) 'ab'가 보인다. 이 'ab'를 하나의 바이트인 'Y'로 치환해보자
ZYdZYac
Y='ab'
또한 위의 ZY 바이트 쌍이 또 중복되므로 이를 'X'로 치환해보자
XdXac
X='ZY'
이제 더이상 병합할 바이트 쌍이 없으므로 BPE를 종료하고 XdXac가 최종 결과물이 된다.
자연어 처리에서의 BPE
자연어 처리에서는 바이트를 글자로 바꿔 생각하면 된다. 즉 단어를 분리한다는 의미이다. BPE를 요약하면 글자(character) 단위에서 점차적으로 단어 집합(vocabulary)을 만들어 내는 Bottom up 방식의 접근을 사용한다.
훈련 데이터에 있는 단어들을 모든 글자 또는 유니코드 단위로 단어 집합을 만들고 가장많이 등장하는 유니그램을 하나의 유니그램으로 통합한다.
기존의 접근
어떤 훈련 데이터로부터 각 단어들의 빈도수를 카운트했다고 해보자. 그리고 각 단어와 각 단어의 빈도수가 기록되어져있는 해당 결과는 임의로 딕셔너리란 이름을 붙였다.

이 훈련 데이터에는 'low'가 4번 , 'lower'은 2번 'newest'는 6번 'widest'는 3번 등장 한다.

단어 집합은 중복을 배제한 단어들의 집합을 의미하기 때문에 이 훈련 데이터의 잔어 집합에는 'low', 'lower' , 'newest', 'widest' 라는 4개의 단어가 존재한다. 만약 테스트 과정에서 lowest가 등장하면 이 단어는 기계가 학습한 적이 없기 때문에 OOV가 발생하게 된다. 그렇다면 BPE를 적용한다면 어떻게 될까?
BPE를 적용
이제 위의 딕셔너리에 BPE를 적용해보자. 우선 딕셔너리의 모든 단어들을 글자(character) 단위로 분리한다. 이 경우 딕셔너리 아래의 사진과 같아진다.
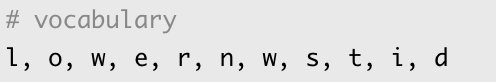
간단히 말해 초기 구성은 글자 단위로 분리된 상태이다.
BPE의 특징은 알고리즘의 동작을 몇회 반복(iteration)할 것인지를 사용자가 정한다는 점이다. 여기서는 총 10회를 수행한다고 가정한다. 즉, 가장 빈도수가 높은 유니그램 쌍을 하나의 유니그램으로 통합하는 과정을 총 10회 반복한다. 위의 dictionary를 기준으로 가장 빈도수가 높은 유니그램의 쌍은 (e, s)이다. 왜냐하면 newest에서도 es가 6번 widest에서도 es도 3번 총 9번 등장하기 때문이다. 물론론 st도 9번이지만 es가 더 앞에 있으므로 이를 먼저 선택한다. 순서는 상관 없다.
1회 - 딕셔너리를 참고로 하였을 때 빈도수가 가장 높은 (e,s)의 쌍을 es로 통합한다.
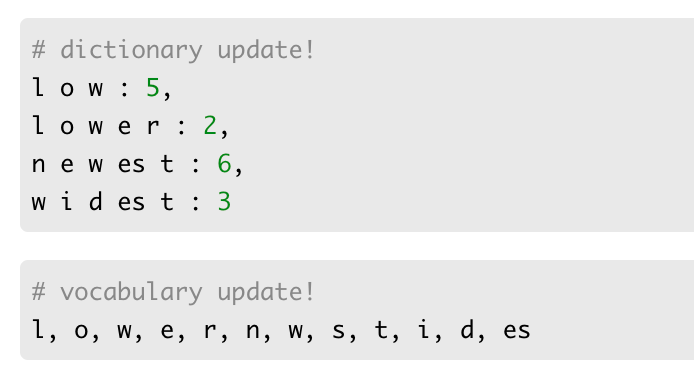
2회 - 빈도수가 9로 가장 높은 (es, t) 쌍을 est로 통합한다.

3회 - 빈도수가 7로 가장 높은 (l,o)의 쌍을 lo로 통합한다.

이와 같은 방식으로 총 10회 반복하였을 때 얻은 딕셔너리와 단어 집합은 아래와 같다.

만약 훈련된 데이터 중에서 어떤 서브워드도 존재하지 않는 단어가 들어오면 어떻게 될까? 그럴 경우에는 모든 알파벳으로 분리가 된다. BPE외에도 BPE를 참고하여 만들어진 Wordpiece Model이나 Unigram Language Model Tokenizer와 같은 서브워드 분리 알고리즘이 존재한다.
알고리즘 실행 순서
- 충분히 큰 훈련데이터를 준비한다(ex. corpus).
- subword vocabulary에 적용할 이상적인 subword vocabulary size를 정한다;
- 단어를 character단위로 자르고 마지막에 "</w>" 토큰과 단어의 빈도수를 붙인다. 예를 들어 "low"의 빈도가 5개이면 "l o w <\w>:5 라고 바꿔쓸 수 있다.
- 높은 빈도수를 나타내는 pair를 묶어 새로운 subword를 만들어낸다.
- step2에서 정의한 vocabulary size에 도달하거나 다음으로 가장 높은 빈도수를 나타내는 pair가 1일 때(즉 더 이상 겹쳐지는 pair가 없으면)까지 step 4를 반복한다.
WordPiece Model
WordPiece Model(WPM)은 BPE의 변형 알고리즘으로 BPE는 빈도수에 기반하여 가장 많이 등장한 쌍을 병합하는 것과는 달리, 병합 되었을 때 코퍼스의 likelihood를 가장 높이는 쌍을 병합한다. 참고로 BERT를 훈련하기 위해 WPM이 사용되었고 BERT는 768의 차원으로 이루어진 32000개 가량의 token이 있다.
WordPiece Model에서 subword는 ##로 시작하는 것을 볼 수 있는데 이것은 와일드카드를 나타내는 것이아니라 그냥 subword라는 것을 알려주는 flag의 개념이다. 단 문장의 처음으로 시작하는 서브워드는 ##가 없다.
알고리즘의 실행순서
- 충분히 큰 훈련 데이터를 준비한다.(corpus)
- subword vocabulary에 적용할 이상적인 subword vocabulary size를 정한다.
- 단어를 character 단위로 자른다.
- step 3 data를 기반으로 language model을 만든다.
- 3에서 만든 vocabulary에서 만들 수 있는 조합중에 subword vocabulary 에 추가하였때 training data의 likelihood를 가장 많이 상승시키는 새로운 word unit을 추가한다.
- step2에서 정의한 vocabulary size에 도달하거나 특정 thereshold 보다 likelihood increase가 떨어지면 step5를 반복한다.
Unigram Language Model Tokenizer
유니그램 언어 모델 토크나이저는 각각의 서브워드 들에 대해서 손실을 계산한다. 여기서 서브 단어 손실이라는 것은 해당 서브워드가 단어 집합에서 제거 되었을 경우, 코퍼스의 likelihood가 감소하는 정도를 말한다. 이렇게 측정된 서브워드들을 손실의 정도로 정렬하여, 최악의 영향을 주는 10%~20%의 토큰을 제거한다. 이것을 원하는 단어 집합의 크기에 도달할 때 까지 반복한다.
알고리즘 실행순서
- 충분이 큰 훈련 데이터를 준비한다.(corpus)
- subword vocabulary에 적용할 이상적인 vocabulary size를 정한다.
- 주어진 word sequence를 사용하여 word occurrence probability를 최적화 한다.
- Compute the loss of each subword 각 subword의 loss를 계산한다.
- step4에서 계산한 loss를 기준으로 하여 subword를 sort하고 이중 상위 X%의 subword들을 살린다. OOV를 피하기 위해서 character level의 subword은 subset에 항상 포함되도록 하는것이 권장된다.
- step5에서 변화가 없거나 step2에서 정의한 vocabulary size에 도달하기 전까지 step 3 -5 를 반복한다.
3개를 비교하자면
- BPE: 사전에 정의한 vocabulary size에 도달하기 전까지 매 iteration마다 단지 등장 빈도수만을 확인하여 가장 많이 등장한 pair를 subword set에 추가한다.
- WordPiece: BPE와 비슷하고 potential merges를 확인하기 위해 subword등장 빈도수를 사용한다, 하지만 최종 결정은 merged token의 likelihood를 기준으로 한다. Unigram과 공통점은 subword vocabulary를 구현하기 위해 language model을 사용한다는 것이다.
- Unigram: 등장 빈도수는 전혀 사용하지 않고오직 확률모델을 사용한다. 대신 확률 모델을 사용하여 language Model을 훈련시킨다. 가장 적게 전반적인 likelihood를 개선한 token들을 삭제하고 final token limit을 만날 때까지 계속한다.
Sentencepiece
구글에서는 Sentencepiece라는 좋은 Wrapper?를 만들어 냈다. 즉, 새로운 데이터등에 BPE와 Unigram등을 사용하여 새로운 tokenizer를 만들 수 있다. wordpiece 방법을 제외한 BPE, Unigram, 그리고 단어별로 tokenize를 진행하는 word, 글자단위로 tokenize를 진행하는 char을 만들 수 있다.
다른 블로그에서 이미 충분히 코드 사용법을 설명했기 때문에 이는 따로 첨부하지 않는다.
대신 실행예시만 posting 하겠다. 한글은 korean wiki 데이터를 사용하였고 영어는 직접 만들었다. 먼저 tokenize 되었다는것은 그만큼 많이 사용되었다는 것이다.
model_type이 char일때(영어)
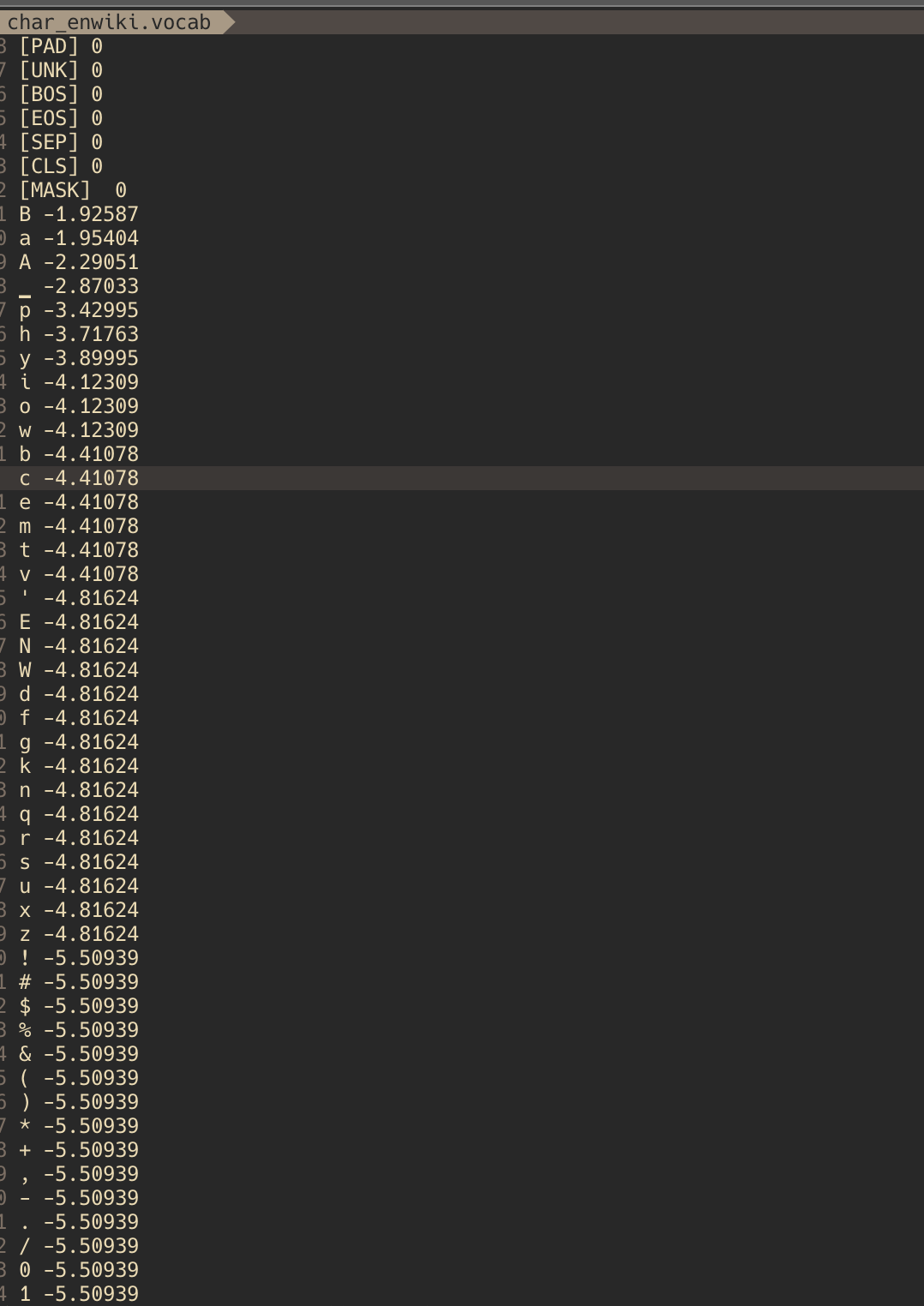
model_type이 char일때(한글)

model_type 이 word 일때(한글)
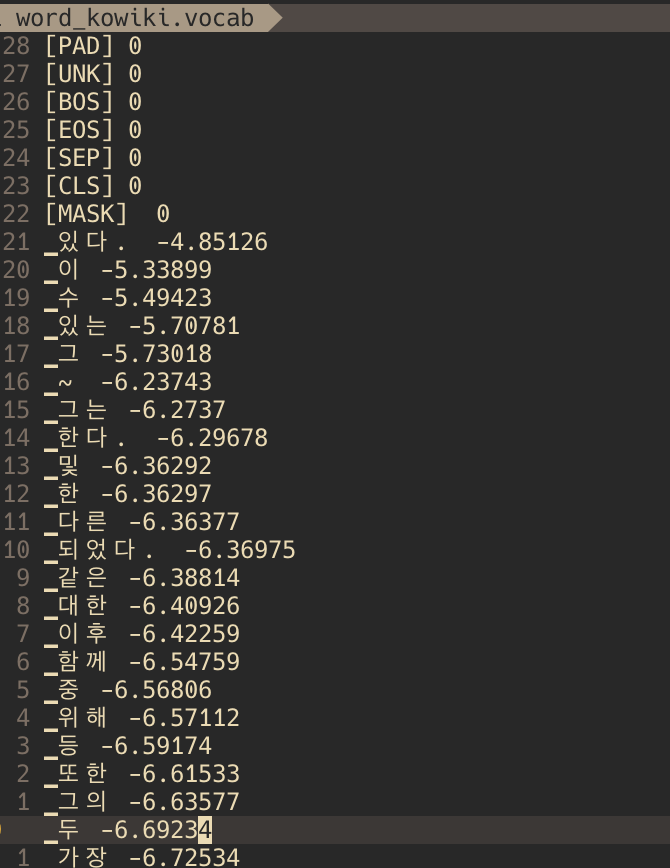
model_type이 BPE였을때(한글)

출처
github.com/google/sentencepiece
huggingface.co/transformers/tokenizer_summary.html#wordpiece
Summary of the tokenizers — transformers 4.2.0 documentation
Summary of the tokenizers On this page, we will have a closer look at tokenization. As we saw in the preprocessing tutorial, tokenizing a text is splitting it into words or subwords, which then are converted to ids through a look-up table. Converting words
huggingface.co