B-Tree 와 B+Tree 의 차이점
B-Tree 와 B+Tree 는 더 효율적이게 원하는 데이터를 탐색할 수 있는 자료구조의 일종 으로 주로 데이터베이스의 인덱스를 사용할 때 쓰이는 알고리즘입니다.
이번 포스팅에서는 B-Tree 와 그것의 변형된 알고리즘인 B+ Tree 에 대해 알아보겠습니다.
Tree 는 DB에 한정짓지 않더라도 탐색 시간을 단축할 수 있다는 장점 때문에 자주 사용이됩니다.
B-Tree 의 핵심은 데이터가 정렬 된 상태로 유지되어 있다는 것입니다.

B-Tree 는 위 그림과 같이 생겼습니다. Binary-Tree 라고 오해를 하지만 Balanced-Tree 를 의미합니다. 자식이 2개 이상 가능합니다.
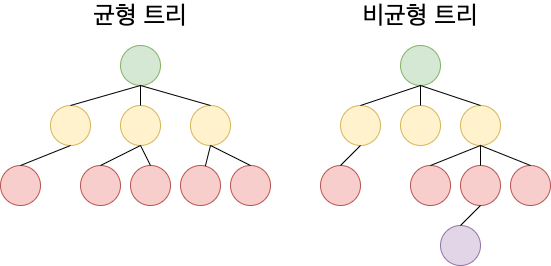
B-tree 는 균형 트리로 루트로부터 리프까지의 거리가 일정한 트리 구조입니다. 이렇게 균형을 유지할 경우 어떤 데이터를 검색할 때 빠른 속도로 데이터를 찾을 수 있습니다. 하지만 만약 트리의 노드가 수정되어야 한다면 재정렬을 해줘야 하기 때문에 수정시 약점이 있습니다.

MySQL의 InnoDB에서 사용되는 B+Tree 는 리프 노드를 제외하고 값을 담아두지 않기 때문에 하나의 블록에 더많은 Key 들을 담아 둘 수 있다 는 장점이 있습니다. 이는 곧, 트리의 높이가 낮아짐을 나타냅니다.
또한, 풀 스캔시 B+Tree는 리프 노드에 데이터가 모두 있기 때문에 한번의 선형 탐색만 하면 되기 때문에 B-Tree 에 비해 빠르다 는 장점이 있습니다. 참고로 같은 레벨의 노드에서는 Double Linked List 를 사용하고 자식 노드는 Single Linked List 를 사용합니다.
결론적으로 표로 비교를 해보면 다음과 같습니다.
구분B-TreeB+Tree
| 데이터 저장 | 모든 노드는 데이터 저장 가능 | 리프노드에만 데이터 저장 가능 |
| 트리의 높이 | 높음 | 낮음(한 노드 당 Key 를 많이 담을 수 있습니다.) |
| 풀 스캔시, 검색 속도 | 모든 노드 탐색 | 리프 노드에서 선형 탐색 |
| 키 중복 | 없음 | 있음(리프 노드에 모든 데이터가 있기 때문에) |
| 검색 | 자주 access 되는 노드를 루트 노드에 가까이 배치하여 루트 노드에서 가까울 경우, 브랜치 노드에도 데이터가 존재하기 때문에 빠름 | 리프 노드까지 가야 데이터 존재 |
| 더블 링크드 리스트 | 없음 | 리프 노드끼리 링크드 리스트로 연결되어있음 |